


Introduction
Are you any good as a therapist? Overall, therapists seem to be quite a confident group. A study by Walfish, McAllister, O’Donnell, and Lambert (2012) asked 129 therapists to compare their psychotherapy results to those of their peers. They found that 25% of the therapists estimated that their results were in the upper 10% of all therapists, and not a single one estimated that their results were below average. Obviously these are statistical impossibilities, suggesting that therapists are generally overconfident.
The December 2015 issue of Psychotherapy was a special issue devoted to progress monitoring and feedback in mental health care. As Wampold (2015) reiterated, Clement (1994) asked therapists, “Are you any good?” Clement suggested that therapists had a professional and ethical obligation to systematically evaluate their own outcomes. To his credit, Clement followed his own suggestion—he evaluated himself over his entire career (683 cases).
Decades of psychotherapy research have shown that some therapists perform exceptionally well while others do not (Wampold & Brown, 2005). Do years of experience matter? Likely not. Among other things, Clement (1994) learned from his cases that his results had not improved with experience. There is additional evidence that this is not so (e.g., Minami et al., 2009).
Is it the kind of therapy that matters then? Very unlikely. Specific method of therapy seems to contribute very little to clients’ progress (Wampold & Imel, 2015). Therefore, your therapist telling you that s/he practices “cognitive behavioral therapy (CBT)” provides you with no assurance that s/he’s any good.
To assess a therapist’s effectiveness, it is necessary to have a well-developed methodology that addresses multiple measurement challenges such as use of different questionnaires, differences in case mix, and small sample sizes. We and our collaborators have attempted to address these over the years using data from thousands of therapists, culminating in a series of articles (e.g., Minami, Wampold, Serlin, Kircher, & Brown, 2007; Minami, Serlin, Wampold, Kircher, & Brown, 2008a; Minami et al., 2008b; Minami et al., 2009; Minami, Brown, McCulloch, & Bolstrom, 2012; Brown, Simon, Cameron, & Minami, 2015).
The purpose of this brief report is to present the newest results of applying this methodology to the dataset from the ACORN collaboration, which includes over 4000 therapists working in diverse clinical settings treating a wide variety of presenting problems.
Therapists and Clients
We selected therapists who had:
- At least 5 cases with 2 or more assessments and,
- Clients with intake scores that were severe enough to be in a clinical range.
A total of 2,820 therapists met this threshold, with a combined sample size of 162,168 cases.
As is typical of outpatient mental health care, just over 60% of the clients were female and roughly 1/3 of cases were youth under the age of 18. No other demographics variables were available for the entire database due to idiosyncratic reporting requirements across agencies.
While most of the questionnaires were developed as part of the ACORN collaboration, a number of sites used other well-developed measures such as the OQ-45, BASIS-32, PHQ9, GAD7, and the ORS. These questionnaires demonstrated very similar factor structures and produced comparable effect sizes.
Factor analyses confirmed that all questionnaires had items that loaded heavily on a common factor, which we refer to as global distress. For these reasons, we were comfortable combining the results across different questionnaires and had confidence that the results would hold with other well-developed questionnaires that are used in measuring psychotherapy.
Statistical Method
The methodology has been described at length in prior articles, and thus what follows is a brief summary. The difference between posttreatment and pretreatment (i.e., change score) is standardized to an effect size (Cohen’s d) simply by dividing the change score by the standard deviation of the questionnaire at intake (Cohen, 1988; Becker, 1988).
However, it is important to bear in mind that the magnitude of the change score is highly dependent on the pretreatment score. Clients with high levels of distress will tend to report much more change than those with very little distress at intake. For this reason, clients with intake scores that are not considered within a clinical range are commonly excluded from analyses, as we did here. This cutoff also has the advantage of selecting a sample that is more comparable to those found in clinical trials for psychotherapy for various disorders (Minami et al., 2007, 2008b).
The methodology for benchmarking therapists was extended in two ways (Minami et al., 2012):
1. Rather than using raw effect sizes, severity adjusted effect sizes (SAES) were calculated for each case. This approach had the advantage of controlling for differences in case mix (e.g., diagnoses, intake scores) from one therapist to another.
2. The use of hierarchical linear modeling (HLM; also known as multilevel modeling) allowed for estimation of therapists’ performance under the reality that therapists in the database are only a fraction of the therapists out in the world and that their clients also are likely a fraction of their cases. This method thus leads to a more conservative yet reliable estimate of the therapists’ performance, as will be illustrated below.
Results
The following table presents the mean and distribution of therapists’ performance in both raw average severity adjusted effect sizes (SAES) and hierarchical linear modeling (HLM)-estimated average SAES.
The table breaks out the results by the number of clients that the therapists have in the database in order to demonstrate the benefits of using HLM to estimate therapists’ effect sizes.
Table 1: Distribution of therapist effect size as a function of sample size
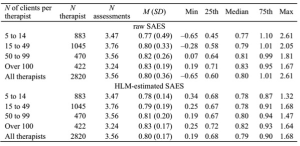
As is apparent, raw SAES calculations show greater differences in performance among therapists when the number of clients per therapist is low, which questions the reliability of the estimates. On the other hand, with the same data, HLM produces estimates that are more convergent regardless of the number of clients. It is theoretically and statistically very unlikely that therapists who have lower number of clients in the database differ greatly as compared to therapists who have higher number of clients. Therefore, we believe that HLM produces more reliable estimates of therapists’ performance.
So, how should the HLM results be interpreted?
To explain this, we will look at the most reliable results of the HLM-estimated SAESs, which is that of therapists with over 100 cases. The mean effect size of d= 0.83 indicates that, on average, a client has roughly 80% chance that her/his symptoms at the end of treatment would be better than the average client’s symptoms at the beginning of treatment.
Similarly, the effect size of the lowest-performing therapist at d= 0.25 indicates that a client has only 60% chance that her/his symptoms at the end of treatment would be better than the average client’s symptoms at the beginning of treatment. Not much improvement from a 50/50 chance.
On the other hand, the effect size of the highest-performing therapist at d= 1.64 indicates that a client has roughly 95% chance that her/his symptoms at the end of treatment would be better than the average client’s symptoms at the beginning of treatment.
If you were a client, which therapist would you choose?
The story gets worse. At least one study estimated how much clients change if they were in the wait-list condition and found that the effect size was d= 0.15 (Minami et al., 2007). This suggests a 56% chance of getting better without any treatment, which is only 4% less than being treated by the lowest-performing therapist.
Further, as the number of assessments suggest, it is highly unlikely that the better performances of therapists with a large number of clients in the database are attained by using more sessions.
Therefore, if one were to assume that the rate of improvement is consistent, the lowest-performing therapist would require 3 times the number of sessions as compared to the average therapist and as much as 7 times the number of sessions as compared to the highest-performing therapist.
Discussion
The overall result shows a robust estimate of performance for a large group of therapists. These results also illustrate the pitfalls of trying to evaluate therapist effectiveness using simple averages rather than employing HLM. Finally, the table provides some guidance for therapists trying to interpret their own performance, provided they measure their outcomes.
It goes without saying that benchmarking performance is not an exact science, and thus there are an infinite number of reasons why therapists’ performances differ. In addition, the results cannot provide sufficient explanation for any particular therapist with a particular set of clients. Regardless, we believe that the results provide unwavering confidence that measuring performance, albeit with imperfections, is better than not measuring performance.
As this sample demonstrates, there are substantial differences in therapists’ performance. Fortunately, most therapists produce results comparable to what we would expect from well-conducted clinical trials, which is an effect size of approximately d= .80. About 25% have results that exceed this benchmark by 10% or more (d => .90), while about 25% will fall short by a similar amount (d < .68).
The question “Are you any good?” only makes sense in the context of “Compared to what?” Benchmarking provides therapists with a way to answer this question and to evaluate if their performance is improving over time.
Wampold (2015), summarizing the evidence from the articles in the special issue, concluded that sufficient evidence exists to adapt one of the feedback systems described, if not something similar. We wholeheartedly agree and assert, as did Clement (1994), that it is unethical to not monitor progress and provide feedback on performance.
After all, without measuring your outcomes, you have no idea if you’re any good.
About the Author

Ashley Simon, M.S.
Ashley Simon began working in clinical Psychology labs as an undergraduate at the University of Utah before leaving the field briefly to obtain a Master's degree in Middle East Studies and Linguistics. Over her 9 years at ACORN, Ashley has worked as the head of Risk Assessment, QA, has coauthored on the collaboration's psychometric research, and now directs ACORN's content and training initiative.
Citation
References
Becker, B. J. (1988). Synthesizing standardized mean-change measures. British Journal of Mathematical and Statistical Psychology, 41, 257-278. doi:10.1111/j.2044-8317.1988.tb00901.x
Brown, G. S., Simon, A., Cameron, J., & Minami, T. (2015). A collaborative outcome resource network (ACORN): Tools for increasing the value of psychotherapy. Psychotherapy, 52, 412–421. doi: 10.1037/pst0000033
Clement, P. W. (1994). Qualitative evaluation of 26 years of private practice. Professional Psychology: Research and Practice, 25, 173-176. doi: 10.1037/07357028.25.2.173
Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Hillsdale, N.J: Lawrence Erlbaum Associates.
Minami, T., Brown, G. S., McCulloch, J., & Bolstrom, B. J. (2012). Benchmarking therapists: Furthering the benchmarking method in its application to clinical practice. Quality and Quantity, 46, 1699-1708. doi:10.1007/s11135-011-9548-4
Minami, T., Davies, D. R., Tierney, S. C., Bettmann, J. E., McAward, S. M., Averill, L. A., Huebner, L. A., Weitzman, L. M., Benbrook, A. R., Serlin, R. C., & Wampold, B. E. (2009). Preliminary evidence on the effectiveness of psychological treatments delivered at a university counseling center. Journal of Counseling Psychology, 56, 309-320. doi:10.1037/a0015398
Minami, T., Serlin, R. C., Wampold, B. E., Kircher, J. C., & Brown, G. S. (2008a). Using clinical trials to benchmark effects produced in clinical practice. Quality and Quantity, 42, 513-525. doi:10.1007/s11135-006-9057-z
Minami, T., Wampold, B. E., Serlin, R. C., Kircher, J. C., & Brown, G. S. (2007). Benchmarks for psychotherapy efficacy in adult major depression. Journal of Consulting and Clinical Psychology, 75, 232-243. doi:10.1037/0022-006X.75.2.232
Minami, T., Wampold, B. E., Serlin, R. C., Hamilton, E. G., Brown, G. S., & Kircher, J. C. (2008b). Benchmarking the effectiveness of psychotherapy treatment for adult depression in a managed care environment: A preliminary study. Journal of Consulting and Clinical Psychology, 76, 116- 124. doi:10.1037/0022-006X.76.1.116
Walfish, S., McAlister, B., O’Donnell, P., Lambert, M. J. (2012). An investigation of self-assessment bias in mental health providers. Psychological Reports 110, 639-644. doi 10.2466/02.07.17.PR0.110.2.639-644
Wampold, B. E. (2015). Routine outcome monitoring: coming of age-with the usual developmental challenges. Psychotherapy 52, 458-462. doi:.org/10.1037/pst0000037
Wampold, B. E., & Brown, G. S. (J.) (2005). Estimating variability in outcomes attributable to therapists: A naturalistic study of outcomes in managed care. Journal of Consulting and Clinical Psychology, 73, 914-923. doi:10.1037/0022-006X.73.5.914
Wampold, B. E., Imel, Z. E. (2015). The great psychotherapy debate: The evidence for what makes psychotherapy work (2nd ed.). New York, NY: Routledge.
Comments
Be the first to share your thoughts.
Leave a comment
Your email address will not be published. Comments are reviewed before they appear.